Looker, a powerful business intelligence tool, employs data modeling to help organizations analyze and visualize their data. A critical aspect of Looker’s data modeling involves defining relationships between different views (or tables) in the LookML model. These relationships, defined by the types of joins, dictate how data from one table is combined with data from another. Understanding these join types and knowing when to use each can significantly impact the accuracy and performance of your data analysis.
Types of Relationships in Looker
1. One-to-One (one_to_one)
- Definition: In a one-to-one relationship, each row in one table corresponds exactly to one row in another table. This relationship is used when two tables share a direct and unique connection through their keys.
- Example: Consider a database where one table holds employee records and another stores their corresponding payroll information. If both tables use a unique employee ID as the key, each row of the employee table will match exactly one row in the payroll table based on the employee ID.
2. Many-to-One (many_to_one)
- Definition: A many-to-one relationship occurs when multiple rows in one table can be associated with a single row in another table. This type of join is common when the second table holds unique keys that the first table references.
- Example: A company might have a table of customer transactions and another table with customer profiles. Multiple transactions (many) can relate to a single customer profile (one), but each transaction row will link back to only one customer profile based on customer ID.
3. One-to-Many (one_to_many)
- Definition: A one-to-many relationship is the inverse of many-to-one. Here, one row in the first table is linked to multiple rows in the second table.
- Example: A product catalog table may link to a table of order details. One product can appear in multiple orders, making it a one-to-many relationship from products to orders.
4. Many-to-Many (many_to_many)
- Definition: In a many-to-many relationship, rows in the first table can relate to multiple rows in the second table, and vice versa. This relationship often requires a third table, known as a junction or bridge table, which holds foreign keys that reference the primary keys in the two other tables.
- Example: In a school database, a table of students and a table of classes would form a many-to-many relationship since students can enroll in multiple classes and each class can include multiple students. The junction table might include entries for each student-class pair.
Practical Example Using Looker Joins
Let’s consider a real-world example involving two datasets: semrush_keyword_position and semrush_site_visibility.
- semrush_keyword_position: This table records daily keyword performance for different shops within a site, with multiple entries per site because of variations in keywords and dates.
- semrush_site_visibility: This table captures the daily visibility metric for each site.
Importance of Selecting the Correct Join Type in Looker
In our ongoing example involving semrush_keyword_position and semrush_site_visibilitymany_to_one relationship exists between the tables due to the structure of the data, we opt for a one_to_one relationship for a specific analytical purpose. Let’s explore the implications:
- semrush_keyword_position: Contains multiple entries per site per day, representing different keywords.
- semrush_site_visibility: Holds a single visibility metric per site per day.
Potential Misuse of Many-to-One Relationship:
If you were to use a many_to_one relationship from semrush_keyword_position to semrush_site_visibility
Issue with Aggregate Calculations: When performing aggregate calculations or transformations on the joined data, the visibility metric from the semrush_site_visibilitysemrush_keyword_position table. This could lead to several issues:
- Duplication of Metrics: Every keyword performance entry would carry the same visibility value, which when aggregated (e.g., averaged or summed), would artificially inflate or misrepresent the actual visibility metric. For instance, if you were to average visibility across all keywords for a site on a particular day, the resulting number would inaccurately reflect multiple times the actual site visibility.
- Skewed Data Interpretation: This duplication makes it difficult to accurately analyze how visibility correlates with keyword performance since the visibility data is not uniquely paired but rather redundantly spread across multiple entries.
Here is the example result if you choose many_to_one join. As you can see, site’s visibility gets duplicated.
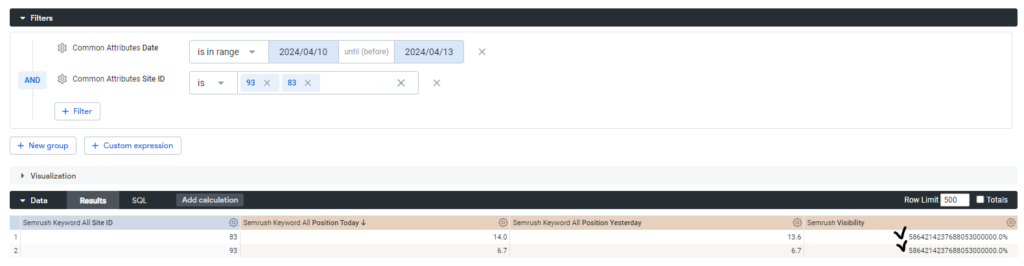
Correct Use of One-to-One Relationship:
By using a one_to_one relationship and ensuring that the join condition includes both site_id and date, each keyword entry is accurately paired with the correct, singular visibility metric for its corresponding site on that specific day. This approach prevents the misrepresentation of visibility data across multiple keywords.
LookML Code Example:
explore: semrush_keyword_position {
join: semrush_site_visibilty {
type: inner
relationship: one_to_one
sql_on: ${semrush_keyword_position.site_id} = ${semrush_site_visibilty.site_id} AND
${semrush_keyword_position.date} = ${semrush_site_visibilty.date} ;;
}
}Explanation: This setup ensures that each keyword’s performance data from semrush_keyword_all is correctly enriched with the actual site visibility from semrush, reflecting the true performance and visibility metrics without duplication or misrepresentation.
If you change to one_to_one, you will get this correct visibility.
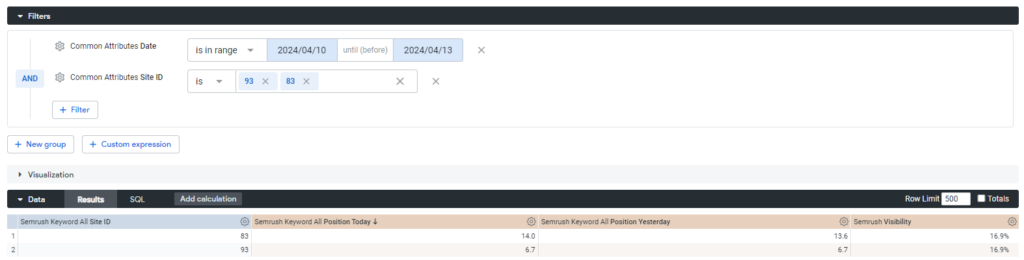
Conclusion:
Choosing the right type of join in Looker is not just a matter of matching table relationships but also understanding the analytical goals and how data should be represented to maintain accuracy. The one_to_one relationship, in this case, provides a precise and truthful representation of the data, supporting more accurate and meaningful insights.
For further reading on Looker’s join types and relationships, please visit the official Looker documentation. To explore more posts related to Looker and other growth hacking tips, check out my blog.