GCP 마이그레이션을 고민하고 계신가요? 오늘은 Google Cloud Platform(GCP)를 활용하여 ETL(Extract, Transform, Load) 토폴로지를 어떻게 구성하는지 예시를 공유해보려고 합니다. 이를 통해 GCP 아키텍처를 구성하는 다양한 서비스들이 어떻게 활용되는지 함께 살펴보겠습니다.
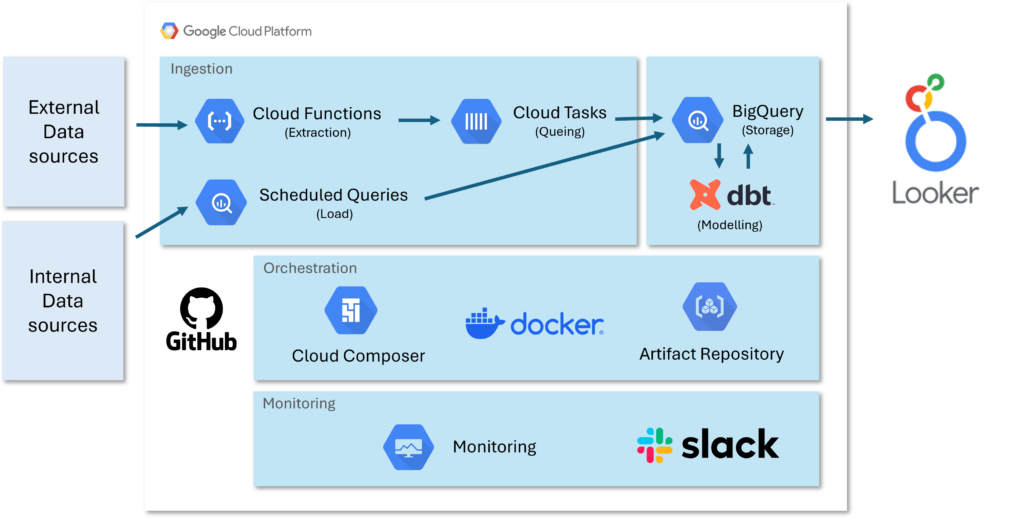
■ 데이터 소스
먼저, 데이터 파이프라인의 출발점인 데이터 소스에 대해 이야기해볼게요. 데이터 소스는 두 가지 유형으로 나눠볼 수 있습니다.
- 외부 데이터 소스(External Datasource): API를 통해 데이터를 수집하는 모든 외부 소스를 말합니다. 예를 들어, 웹사이트 트래픽 분석 도구인 GA4(Google Analytics 4), 검색 퍼포먼스 모니터링 도구인 GSC(Google Search Console)나 SemRush 등이 있습니다. 이러한 데이터들은 마케팅 전략 수립이나 시장 분석에 필수적이죠.
- 내부 데이터 소스(Internal Datasource): 회사의 프론트엔드나 백엔드 시스템에서 직접 수집하는 데이터입니다. 예를 들어, 웹사이트에서 발생하는 클릭 ID 데이터나 특정 페이지의 요소 위치 데이터, 구매 데이터 등이 있습니다. 이는 사용자 경험 개선과 제품 최적화에 중요한 역할을 합니다.
■ 클라우드 함수(Cloud Functions)로 데이터 추출하기
데이터 추출 단계에서는 **클라우드 함수(Cloud Functions)**를 활용합니다. 클라우드 함수를 사용하면 모듈화를 통해 스케일업이 용이해집니다. 예를 들어, GA4 데이터 추출에 특화된 함수를 하나의 모듈로 만들어 관리할 수 있습니다.
장점:
- 서버 관리 불필요: 인프라 관리에 대한 부담 없이 코드 실행이 가능합니다.
- 자동 확장성: 클라우드 함수는 트래픽의 양에 관계없이 자동으로 확장됩니다. 즉, 수백 개의 요청이 동시에 발생해도 클라우드 함수는 이를 자동으로 처리하고 확장하여 성능 저하 없이 실행됩니다.
- 비용 효율성: 사용한 만큼만 비용이 발생합니다.
단점:
- 실행 시간 제한: 함수별 최대 실행 시간이 제한됩니다.
- 상태 비유지성: 함수 실행 간 상태를 유지하지 않습니다.
■ 클라우드 태스크(Cloud Tasks)로 병렬 처리하기
퍼포먼스를 높이기 위해 **클라우드 태스크(Cloud Tasks)**를 사용하여 함수를 병렬로 실행합니다. 이를 통해 대량의 데이터를 효율적으로 처리할 수 있습니다.
장점:
- 비동기 작업 처리: 클라우드 태스크는 큐(queue) 기반의 비동기 작업 처리를 지원합니다. 즉, 작업을 대기열에 넣어 처리할 수 있어, 여러 작업을 동시에 처리하거나 순차적으로 실행할 수 있습니다.
- 높은 확장성: 작업의 양에 관계없이 클라우드 태스크는 자동으로 작업을 관리하고 확장하여 처리 성능을 유지합니다.
단점:
- 복잡한 설정: 초기 설정과 관리가 복잡할 수 있습니다.
- 추가 비용 발생: 서비스 사용에 따른 비용이 있습니다.
■ 내부 데이터 소스와 스케줄된 쿼리(Scheduled Queries)
내부 데이터 소스는 **스케줄된 쿼리(Scheduled Queries)**를 통해 BigQuery로 로드합니다. 이를 통해 BI팀이 최신 데이터를 실시간에 가깝게 활용할 수 있.
장점:
- 자동화된 데이터 업데이트: 일정에 따라 쿼리가 자동으로 실행됩니다.
- 유연한 스케줄링: 비즈니스 필요에 따라 스케줄을 조정할 수 있습니다.
단점:
- 쿼리 비용: 실행 빈도와 데이터 양에 따라 비용이 증가할 수 있습니다.
- 실시간성 제한: 스케줄에 의존하므로 완전한 실시간 처리는 어렵습니다.
■ DBT로 데이터 모델링 및 관리하기
수집된 모든 데이터는 BigQuery에 저장되며, DBT(Data Build Tool)를 사용하여 데이터 모델링과 변환을 수행합니다. DBT는 SQL 기반의 오픈소스 도구로, 데이터 트랜스포메이션 외에도 테스트와 문서화 기능을 제공합니다.
장점:
- 효율적인 데이터 변환: SQL을 활용하여 빠르게 변환 작업을 수행할 수 있습니다.
- 데이터 품질 관리: 테스트 기능을 통해 데이터의 정확성을 유지합니다.
- 모델링 체계 관리 및 재사용성: DBT는 데이터 모델링을 체계적으로 관리할 수 있으며, 코드 기반으로 변환 작업을 자동화하고, 재사용 가능한 파이프라인을 만들어 효율성을 높입니다.
- 버전 관리: 코드 기반으로 변경 사항을 추적할 수 있습니다.
단점:
- 학습 필요성: 팀원들이 새로운 도구를 학습해야 합니다.
- 초기 설정 시간: 환경 설정과 구조 설계에 시간이 소요됩니다.
■ 컴포저(Composer)로 워크플로우 자동화하기
ETL 프로세스를 자동화하고 오케스트레이션하기 위해 **컴포저(Composer)**를 사용합니다. 컴포저는 Apache Airflow를 기반으로 한 관리형 서비스로, DAG 파일을 통해 작업 흐름을 정의합니다.
장점:
- 워크플로우 관리 용이: 복잡한 작업 흐름도 시각적으로 관리할 수 있습니다.
- DAG(Directed Acyclic Graph) 기반 관리: DAG는 ETL 작업 간의 의존성을 시각적으로 표현하는 도구로, 작업의 순서를 정의하고, 효율적인 실행을 조정할 수 있습니다. DAG를 사용하면 복잡한 데이터 흐름을 쉽게 이해하고 관리할 수 있습니다
- 유연한 스케줄링과 모니터링: 작업의 실행 시간과 상태를 쉽게 제어하고 확인할 수 있습니다.
단점:
- 복잡한 초기 설정: 설정 과정이 다소 복잡할 수 있습니다.
- 서비스 비용: 관리형 서비스 사용에 따른 비용이 발생합니다.
■ 도커 이미지(Docker Image)와 클라우드 빌드(Cloud Build)
패키지 설치 및 환경 설정의 일관성을 위해 **도커 이미지(Docker Image)**를 사용합니다. 모든 DBT 관련 패키지를 도커 이미지에 설치하고, 이를 통해 DBT와 컴포저를 실행합니다.
장점:
- 환경 일관성 유지: 도커 이미지는 동일한 환경을 유지할 수 있어 개발 환경과 배포 환경 간의 차이로 인한 문제를 최소화합니다. 따라서 환경 차이로 발생하는 오류를 방지할 수 있습니다.
- 배포 편의성: 이미지 단위로 쉽게 배포 및 업데이트가 가능합니다.
단점:
- 이미지 관리 필요: 이미지의 빌드와 업데이트를 관리해야 합니다.
- 추가 학습 필요: 도커와 컨테이너 기술에 대한 이해가 필요합니다.
■ 테라폼(Terraform)으로 인프라 관리하기
인프라스트럭처 관리를 위해 **테라폼(Terraform)**을 도입하면 좋습니다. 테라폼은 인프라를 코드로 관리할 수 있게 해주는 도구로, 모든 리소스를 한 곳에서 버전 컨트롤하고 자동화할 수 있습니다.
장점:
- 일관된 인프라 배포: 코드로 정의된 인프라를 동일하게 배포할 수 있습니다.
- 변경 사항 추적: 버전 관리를 통해 변경 이력을 확인하고 롤백할 수 있습니다.
- 생산성 향상: 반복적인 작업을 자동화하여 시간을 절약합니다.
단점:
- 초기 학습 비용: 새로운 도구와 언어를 학습해야 합니다.
- 복잡성: 대규모 인프라를 관리할 때는 구조가 복잡해질 수 있습니다.
■ 시크릿 매니저(Secret Manager)로 크레덴셜 관리하기
API 호출에 필요한 크레덴셜은 **시크릿 매니저(Secret Manager)**를 통해 안전하게 관리합니다. 시크릿 매니저는 버전 컨트롤이 가능하며, 필요한 애플리케이션에서 쉽게 불러올 수 있습니다.
장점:
- 보안 강화: 민감한 정보를 안전하게 저장하고 접근 권한을 제어할 수 있습니다.
- 중앙 집중 관리: 여러 애플리케이션에서 동일한 시크릿을 공유할 수 있습니다.
단점:
- 추가 설정 필요: 접근 권한 설정 등 초기 설정에 시간이 필요합니다.
- 비용 발생: 사용량에 따라 비용이 추가될 수 있습니다.
■ 슬랙(Slack) 알림으로 모니터링 강화하기
작업의 성공 여부를 실시간으로 파악하기 위해 **슬랙(Slack)**과 연동하여 알림 시스템을 구축합니다. 특히, 컴포저 작업이 실패하면 즉시 슬랙 채널로 노티 메시지가 전송되도록 니다.
장점:
- 실시간 모니터링: 문제 발생 시 즉각적인 대응이 가능합니다.
- 팀 커뮤니케이션 향상: 팀원들과 정보를 공유하여 협업을 강화합니다.
단점:
- 알림 관리 필요: 불필요한 알림이 많아지면 중요도가 떨어질 수 있습니다.
- 외부 서비스 의존성: 슬랙 서비스에 의존하게 됩니다.
■ Looker로 모델링된 데이터 활용하기
마지막으로, DBT로 모델링한 데이터를 Looker를 통해 사용자들에게 제공합니다. Looker는 강력한 BI(Business Intelligence) 도구로, 데이터를 시각화하고 분석하여 비즈니스 인사이트를 도출하는 데 탁월합니다.
장점:
- 실시간 데이터 접근: 팀원들은 최신 데이터에 실시간으로 접근하여 신속한 의사 결정을 내릴 수 있습니다.
- 대시보드 및 리포트 생성: 복잡한 데이터를 이해하기 쉬운 대시보드와 리포트로 변환할 수 있습니다.
- 커스터마이징 가능: 비즈니스 니즈에 맞게 시각화와 필터를 자유롭게 설정할 수 있습니다.
- 협업 기능: 결과물을 팀원들과 공유하고 피드백을 주고받을 수 있습니다.
단점:
- 학습 곡선: 새로운 인터페이스와 기능에 익숙해지기까지 시간이 필요할 수 있습니다.
- 라이선스 비용: 기업 규모와 사용 범위에 따라 비용이 부담될 수 있습니다.
- 초기 설정 복잡성: 데이터 모델과 권한 설정 등 초기 구성에 신경 써야 합니다.
Tip: Looker와 BigQuery의 연동은 매우 원활하여, 별도의 데이터 이동 없이도 실시간 쿼리가 가능합니다. 또한, Looker의 Explores 기능을 사용하면 비개발자도 쉽게 데이터를 탐색하고 인사이트를 얻을 수 있습니다.
■ 마무리
이렇게 GCP에서의 ETL 토폴로지 구성 방법과 각 서비스의 활용 방안에 대해 공유해보았습니다. GCP의 다양한 서비스들은 개별적으로도 강력하지만, 이들을 적절히 결합하면 더욱 강력하고 유연한 ETL 파이프라인을 구성할 수 있습니다. 클라우드 함수와 태스크를 활용한 데이터 추출 및 병렬 처리, DBT를 통한 데이터 변환, 컴포저로 자동화된 워크플로우 관리, 그리고 도커와 테라폼을 통한 환경 관리까지, 각 도구의 장점을 살려 확장성과 효율성을 극대화한 데이터 아키텍처를 구축할 수 있습니다. GCP 마이그레이션이나 아키텍처 구성을 고민하시는 분들께 도움이 되었길 바랍니다.