Looker는 강력한 BI(Business Intelligence) 툴로, 데이터 모델링을 사용하여 조직이 데이터를 분석하고 시각화할 수 있도록 돕습니다. Looker의 데이터 모델링에서 중요한 부분은 LookML 모델에서 다른 뷰(또는 테이블) 간의 관계를 정의하는 것입니다. 이러한 관계는 조인 유형에 의해 정의되며, 한 테이블의 데이터가 다른 테이블의 데이터와 어떻게 결합되는지를 지시합니다. 이러한 조인 유형을 이해하고 각각을 언제 사용해야 하는지 알아보는 것은 데이터 분석의 정확성과 성능에 중대한 영향을 미칠 수 있습니다.
Looker에서의 관계(relationship) 유형
- 일대일 (one_to_one)
- 정의: 일대일 관계에서는 한 테이블의 각 행이 다른 테이블의 정확히 하나의 행과 일치합니다. 이 관계는 두 테이블이 키를 통해 직접적이고 유일한 연결을 공유할 때 사용됩니다.
- 예제: 하나의 테이블에 직원 데이터가 있고, 다른 테이블에는 해당 직원의 급여 정보를 저장한다고 합시다. 두 테이블 모두 고유한 직원 ID를 키로 갖고 있다면, 직원 테이블의 각 행은 급여 테이블의 정확히 하나의 행과 직원 ID를 기준으로 일치합니다.
- 다대일 (many_to_one)
- 정의: 다대일 관계는 한 테이블의 여러 행이 다른 테이블의 단일 행과 연관될 수 있을 때 발생합니다. 이 유형의 조인은 두 번째 테이블이 첫 번째 테이블이 참조하는 고유 키를 보유할 때 일반적입니다.
- 예제: 고객 거래 내역을 담은 테이블과 고객 프로필을 담은 다른 테이블이 있습니다. 여러 거래(다수)가 단일 고객 프로필(하나)과 관련될 수 있으며, 각 거래 행은 고객 ID를 기준으로 오직 하나의 고객 프로필에 연결됩니다.
- 일대다 (one_to_many)
- 정의: 일대다 관계는 다대일의 반대입니다. 여기서는 첫 번째 테이블의 한 행이 두 번째 테이블의 여러 행과 연결됩니다.
- 예제: 제품 카탈로그 테이블이 주문 세부 정보 테이블에 연결될 수 있습니다. 하나의 제품이 여러 주문에 나타날 수 있어 제품에서 주문까지 일대다 관계가 형성됩니다.
- 다대다 (many_to_many)
- 정의: 다대다 관계에서는 첫 번째 테이블의 행이 두 번째 테이블의 여러 행과 관련될 수 있고, 그 반대의 경우도 마찬가지입니다. 이 관계는 종종 세 번째 테이블인 연결 테이블이 필요하며, 이 테이블은 두 다른 테이블의 기본 키를 참조하는 외래 키를 보유합니다.
- 예제: 학교 데이터베이스에서 학생 테이블과 수업 테이블이 다대다 관계를 형성할 수 있습니다. 학생들은 여러 수업에 등록할 수 있고 각 수업은 여러 학생을 포함할 수 있습니다. 연결 테이블은 각 학생-수업 쌍에 대한 항목을 포함할 수 있습니다.
Looker 조인을 사용한 실제 예제
semrush_keyword_position 및 semrush_site_visibility 두 데이터 세트를 고려해 보겠습니다.
- semrush_keyword_position: 이 테이블은 사이트 내 다양한 상점에 대한 일일 키워드 지표를 가지고 있으며, 키워드와 날짜에 따라 사이트별로 여러 개의 항목이 있습니다.
- semrush_site_visibility: 이 테이블은 각 사이트의 일일 가시성 지표를 가집니다.
Looker에서 올바른 조인 유형 선택의 중요성
semrush_keyword_position 및 semrush_site_visibility 사이에는 엄밀히 말하면 다대일 관계가 있지만, 특정 분석 목적을 위해 일대일 관계를 선택합니다. 자세히 살펴보자면:
- semrush_keyword_position: 사이트별로 하루에 여러 항목을 포함하여 다양한 키워드를 나타냅니다.
- semrush_site_visibility: 하루에 사이트별로 단일 가시성 지표를 보유합니다.
다대일 관계의 잘못된 사용 예:
semrush_keyword_position에서 semrush_site_visibility로 다대일 관계를 사용하면, 첫 번째 테이블의 여러 키워드 항목이 두 번째 테이블의 하나의 가시성 항목과 논리적으로 일치할 수 있습니다. 그러나 이 설정은 분석 오류로 이어질 수 있습니다:
- 집계 계산 문제: 조인된 데이터에서 집계 계산이나 변형을 수행할 때, semrush_site_visibility 테이블의 가시성 지표가 semrush_keyword_position 테이블의 같은 사이트 및 날짜에 대한 여러 키워드 레코드에 잘못 반복될 수 있습니다.
- 지표의 중복: 모든 키워드 성능 항목은 동일한 가시성 값을 가지게 되며, 이를 집계(예: 평균 또는 합계)할 경우 실제 가시성 지표를 부풀리거나 잘못 표현할 수 있습니다. 예를 들어, 특정 날짜의 사이트에 대한 모든 키워드의 가시성을 평균내면, 결과 숫자는 실제 사이트 가시성을 여러 번 반영한 부정확한 수치가 될 수 있습니다.
- 데이터 해석의 왜곡: 이러한 중복은 가시성 데이터가 고유하게 연결되지 않고 여러 항목에 걸쳐 중복되므로 가시성이 키워드 성능과 어떻게 관련되는지 정확히 분석하기 어렵게 만듭니다.
- 따라서 이 예시에서 다대일 관계를 사용하면 다음과 같이 부정확한 사이트 가시성을 보여줍니다.
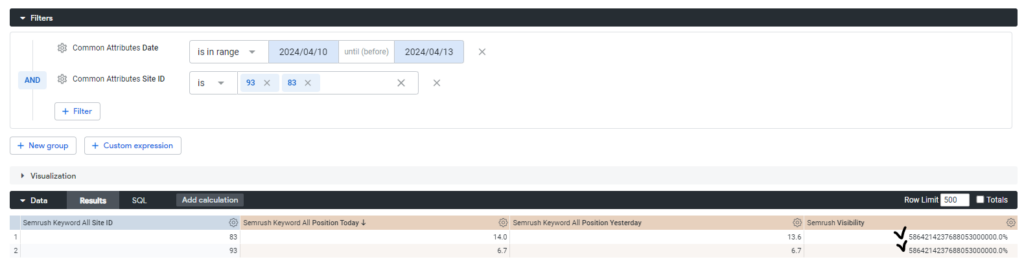
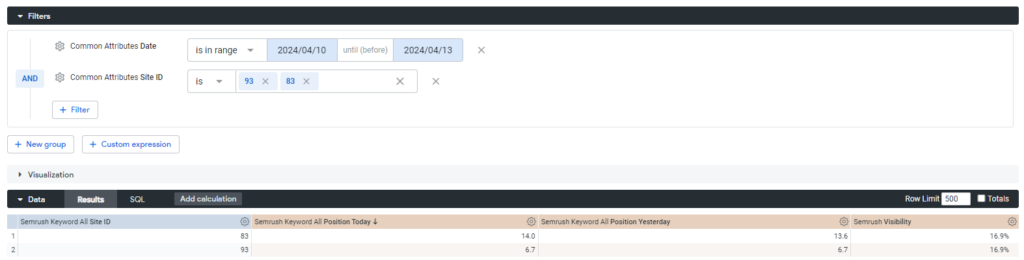
일대일 관계의 올바른 사용:
site_id와 date를 포함하는 조인 조건을 사용하여 일대일 관계를 사용함으로써, 각 키워드 항목은 해당 사이트의 특정 날짜에 대한 정확하고 단일한 가시성 지표와 정확히 연결됩니다. 이 접근 방식은 여러 키워드에 걸쳐 가시성 데이터의 잘못된 표현을 방지합니다.
LookML 코드 예시:
explore: semrush_keyword_position {
join: semrush_site_visibilty {
type: inner
relationship: one_to_one
sql_on: ${semrush_keyword_position.site_id} = ${semrush_site_visibilty.site_id} AND
${semrush_keyword_position.date} = ${semrush_site_visibilty.date} ;;
}
}
이 코드는 semrush_keyword_position의 각 키워드 성능 데이터가 semrush의 실제 사이트 가시성과 정확히 연결되어, 중복이나 잘못된 표현 없이 진정한 성능 및 가시성 지표를 반영하도록 합니다.
Looker에서 올바른 유형의 조인을 선택하는 것은 테이블 관계에 맞추는 것뿐만 아니라 분석 목표를 이해하고 데이터를 정확하게 표현하는 방법을 아는 것을 포함합니다.
Looker의 조인 유형 및 관계에 대한 추가 정보는 공식 Looker 문서를 참조하십시오. Looker 및 기타 성장 해킹 팁과 관련된 더 많은 게시물을 보려면 블로그를 확인해주세요.