Are you considering migrating to GCP? Today, I’d like to share an example of how to configure an ETL (Extract, Transform, Load) topology using Google Cloud Platform (GCP). Through this, we’ll explore how different services within the GCP architecture can be utilized effectively.
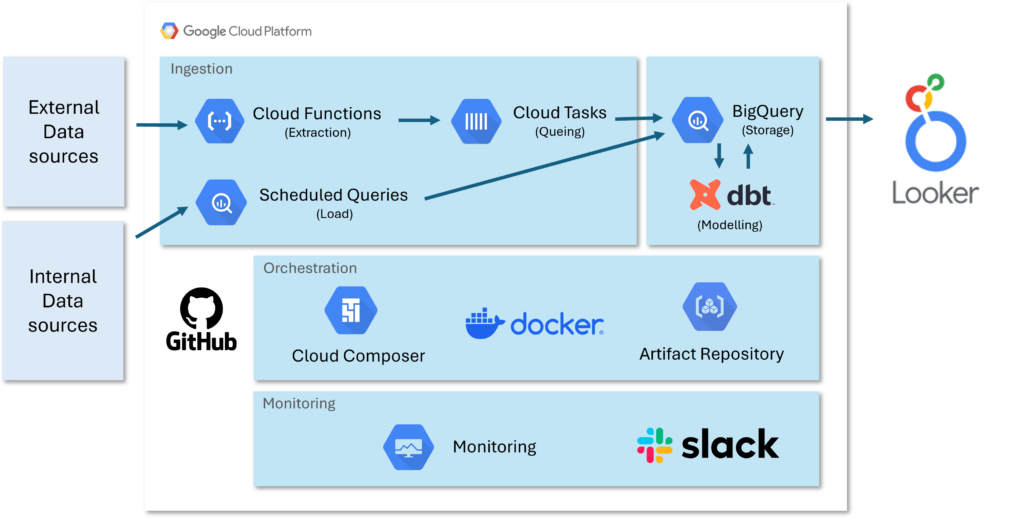
■ Data Sources
First, let’s talk about data sources, the starting point of any data pipeline. Data sources can be categorized into two types:
- External Data Sources: These are all external sources from which data is collected through APIs. Examples include web traffic analytics tools like GA4 (Google Analytics 4), search performance monitoring tools like GSC (Google Search Console), and SemRush. These data sources are essential for formulating marketing strategies and conducting market analysis.
- Internal Data Sources: These are data collected directly from the company’s frontend or backend systems. For instance, click ID data from a website, position data of specific page elements, and purchase data. This data plays a crucial role in improving user experience and optimizing products.
■ Extracting Data Using Cloud Functions
In the data extraction stage, Cloud Functions are utilized. By using Cloud Functions, scaling becomes easier through modularization. For example, you can create a dedicated module for extracting GA4 data.
Advantages:
- No server management: Code can be executed without the burden of managing infrastructure.
- Automatic scalability: Cloud Functions scale automatically, regardless of traffic volume. In other words, even if hundreds of requests occur simultaneously, Cloud Functions will handle them efficiently without performance degradation.
- Cost efficiency: You pay only for what you use.
Disadvantages:
- Execution time limit: There is a maximum execution time for each function.
- Statelessness: Functions do not retain state between executions.
■ Parallel Processing with Cloud Tasks
To improve performance, Cloud Tasks are used to run functions in parallel. This allows for efficient processing of large volumes of data.
Advantages:
- Asynchronous task processing: Cloud Tasks support queue-based asynchronous task processing, meaning tasks can be queued and processed either simultaneously or sequentially.
- High scalability: Cloud Tasks automatically manage and scale tasks, regardless of the volume.
Disadvantages:
- Complex setup: The initial setup and management can be complicated.
- Additional costs: Service usage incurs additional costs.
■ Internal Data Sources and Scheduled Queries
Internal data sources are loaded into BigQuery through Scheduled Queries. This allows the BI team to use near real-time data.
Advantages:
- Automated data updates: Queries run automatically according to a schedule.
- Flexible scheduling: You can adjust the schedule according to business needs.
Disadvantages:
- Query costs: Costs may increase depending on the frequency of execution and the amount of data.
- Real-time limitation: Since it depends on a schedule, it does not provide full real-time processing.
■ Data Modeling and Management with DBT
All collected data is stored in BigQuery, and DBT (Data Build Tool) is used for data modeling and transformation. DBT is an open-source tool based on SQL, which also offers features for testing and documentation.
Advantages:
- Efficient data transformation: You can quickly perform transformations using SQL.
- Data quality management: The testing feature ensures data accuracy.
- Systematic modeling and reusability: DBT enables systematic management of data models, automating transformation work and creating reusable pipelines to improve efficiency.
- Version control: Changes can be tracked in the code.
Disadvantages:
- Learning curve: Team members need to learn a new tool.
- Initial setup time: Setting up the environment and designing the structure takes time.
■ Automating Workflows with Composer
To automate and orchestrate ETL processes, Composer is used. Composer is a managed service based on Apache Airflow, and it defines workflows through DAG files.
Advantages:
- Easy workflow management: Even complex workflows can be managed visually.
- DAG (Directed Acyclic Graph) based management: DAGs visually express dependencies between ETL tasks, helping define the order of execution and ensuring efficient task execution. With DAGs, complex data flows can be easily understood and managed.
- Flexible scheduling and monitoring: You can easily control and monitor the execution time and status of tasks.
Disadvantages:
- Complex initial setup: The setup process can be somewhat complex.
- Service cost: There are costs associated with using the managed service.
■ Using Docker Images and Cloud Build
To ensure consistency in package installation and environment setup, Docker Images are used. All DBT-related packages are installed in the Docker image, which is then used to run DBT and Composer.
Advantages:
- Consistent environment: Docker images ensure the same environment across all stages, preventing issues that arise from differences between development and production environments.
- Ease of deployment: Images can be easily deployed and updated.
Disadvantages:
- Image management: You need to manage the building and updating of images.
- Learning required: Understanding Docker and container technologies is necessary.
■ Managing Infrastructure with Terraform
To manage infrastructure, Terraform is recommended. Terraform allows you to manage infrastructure as code, making it possible to version control and automate all resources from a single location.
Advantages:
- Consistent infrastructure deployment: Infrastructure defined in code can be deployed consistently.
- Track changes: Version control allows you to track changes and roll back if necessary.
- Improved productivity: Automating repetitive tasks saves time.
Disadvantages:
- Learning curve: Learning new tools and languages can be challenging.
- Complexity: Managing large-scale infrastructure can become complex.
■ Managing Credentials with Secret Manager
Credentials required for API calls are securely managed using Secret Manager. Secret Manager allows version control and can be easily accessed by necessary applications.
Advantages:
- Enhanced security: Sensitive information is securely stored, and access permissions are controlled.
- Centralized management: The same secret can be shared across multiple applications.
Disadvantages:
- Additional setup: Initial setup, such as setting access permissions, takes time.
- Cost: Costs may increase depending on usage.
■ Strengthening Monitoring with Slack Alerts
To monitor task success in real time, we integrated Slack for alerts. In particular, when Composer tasks fail, a notification is immediately sent to a Slack channel.
Advantages:
- Real-time monitoring: Immediate response to issues is possible.
- Improved team communication: Information is shared among team members to enhance collaboration.
Disadvantages:
- Notification management: Excessive notifications can reduce their importance.
- Dependency on external services: There is a dependency on the Slack service.
■ Leveraging Modeled Data with Looker
Finally, the data modeled by DBT is provided to users through Looker. Looker is a powerful BI (Business Intelligence) tool that excels in visualizing and analyzing data to extract business insights.
Advantages:
- Real-time data access: Team members can access the latest data in real time, enabling quick decision-making.
- Dashboard and report generation: Complex data can be transformed into easy-to-understand dashboards and reports.
- Customizable: Visualizations and filters can be freely adjusted to meet business needs.
- Collaboration: Results can be shared with team members for feedback and collaboration.
Disadvantages:
- Learning curve: It can take time to become familiar with the new interface and features.
- License cost: Costs can be a burden depending on the size of the company and scope of use.
- Initial setup complexity: Care must be taken when configuring the initial data model and permissions.
Tip: Looker integrates smoothly with BigQuery, allowing real-time queries without the need for separate data transfers. Also, with Looker’s Explores feature, even non-developers can easily explore data and gain insights.
■ Conclusion
We’ve shared how to configure ETL topology on GCP and how to utilize various services. GCP’s individual services are powerful on their own, but when combined effectively, they create an even more robust and flexible ETL pipeline. From data extraction and parallel processing with Cloud Functions and Tasks, to data transformation with DBT, workflow automation with Composer, and environment management with Docker and Terraform, each tool maximizes scalability and efficiency. We hope this has been helpful for those considering GCP migration or architecture design.