Let’s explore the _TABLE_SUFFIX feature in BigQuery SQL, which is frequently used and particularly helpful when querying multiple daily data tables.
Understanding _TABLE_SUFFIX
In BigQuery, _TABLE_SUFFIX is primarily used when querying wildcard tables. Wildcard tables allow you to conveniently query multiple tables based on a specific table name pattern. For example, when analyzing daily log tables, you can query the required data without having to specify each table name individually.
Example: How _TABLE_SUFFIX Works
Suppose you have tables named like my_dataset.my_table_*, where * represents a wildcard. This could match tables such as my_table_20230601, my_table_20230602, and so on. Here, _TABLE_SUFFIX maps to the string that corresponds to the * portion of the table name. For instance, if the table name is my_table_20230601, the value of _TABLE_SUFFIX is 20230601.
This allows you to query only specific tables within a date range. For example, by using _TABLE_SUFFIX BETWEEN '20230601' AND '20230630', you can query tables from June 1, 2023, to June 30, 2023.
Business Case: Querying GA4 Raw Data
A practical example is querying GA4 raw data. GA4 integrates seamlessly with BigQuery, and the collected data is automatically loaded daily into separate tables. These daily tables are typically named in the format events_YYYYMMDD, making it easy to manage event data by date.
Daily tables offer the advantage of efficient data management and fast queries for specific date ranges. For instance, if you need to analyze data for a specific month, you can effortlessly query all the daily tables for that month using wildcards and _TABLE_SUFFIX. This approach significantly improves processing speed and reduces query costs, especially for large datasets.
SQL Example: Analyzing Events Without ga_session_id
Here’s an example SQL query to analyze trends in session_start events where the ga_session_id is missing:
WITH session_start_events AS (
SELECT
PARSE_DATE('%Y%m%d', _TABLE_SUFFIX) AS event_date,
EXTRACT(YEAR FROM PARSE_DATE('%Y%m%d', _TABLE_SUFFIX)) AS year,
EXTRACT(MONTH FROM PARSE_DATE('%Y%m%d', _TABLE_SUFFIX)) AS month,
user_pseudo_id,
(
SELECT ep.value.int_value
FROM UNNEST(event_params) AS ep
WHERE ep.key = 'ga_session_id'
) AS ga_session_id
FROM analytics_1234567.events_*
WHERE event_name = 'session_start'
AND _TABLE_SUFFIX BETWEEN FORMAT_DATE('%Y%m%d', DATE('2023-06-01'))
AND FORMAT_DATE('%Y%m%d', DATE('2024-10-31'))
)
SELECT
year,
month,
COUNT(*) AS total_events,
SUM(CASE WHEN ga_session_id IS NULL THEN 1 ELSE 0 END) AS null_count,
ROUND(SUM(CASE WHEN ga_session_id IS NULL THEN 1 ELSE 0 END) / COUNT(*) * 100, 2) AS null_percentage
FROM session_start_events
GROUP BY year, month
ORDER BY year, month;
</code>Key Points in the Query:
- Wildcard Usage: The query uses
analytics_1234567.events_*to target all tables starting withevents_. - _TABLE_SUFFIX Mapping:
_TABLE_SUFFIXextracts the date part from each table name, enabling the query to process data for a specific date range. - Date Parsing:
PARSE_DATE('%Y%m%d', _TABLE_SUFFIX)converts _TABLE_SUFFIX to a date format, allowing the extraction of event date, year, and month. - Analysis: The query calculates the total number of
session_startevents, counts nullga_session_idvalues, and computes the percentage of null values for each year and month.
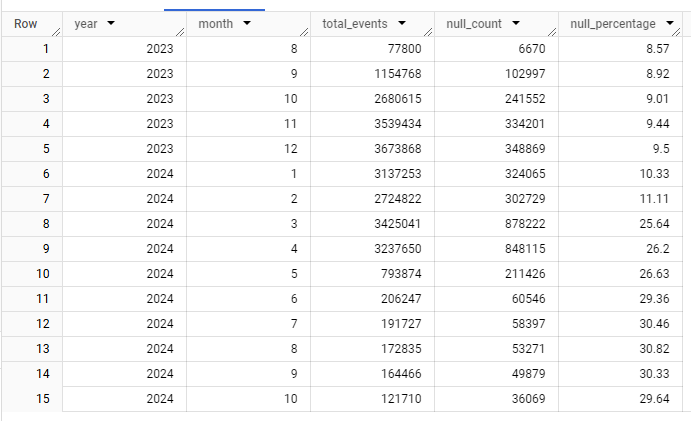
Running this query provides insights into trends in missing ga_session_id values. For instance, you might notice an increase in null values over recent months.
Comparison with MSSQL
One important note is that databases like MSSQL do not natively support features like _TABLE_SUFFIX. In MSSQL, querying multiple tables requires manually combining them using UNION ALL or writing dynamic SQL, making the process more cumbersome. BigQuery’s _TABLE_SUFFIX simplifies such tasks significantly.
Conclusion
The _TABLE_SUFFIX feature is incredibly useful for querying datasets that are partitioned daily. It allows you to efficiently query multiple tables and analyze data for specific periods. When dealing with large-scale data like GA4, this feature can optimize query performance and reduce costs, making it an essential tool for data analysts working with BigQuery.